Table of Contents
Generative adversarial networks and the way they work: an overview
The technology of AI image generation is trending these days so we decided it would be useful to puzzle it out and take a deeper look at the way it works.
The AI image generation uses the generative models of machine learning algorithms. We can identify three perspective types of these models:
- Autoregressive models
- Variational autoencoders (VAE)
- Generative adversarial networks (GAN)
The best results on image generation that are almost indistinguishable from the natural images are generated by the GAN networks. This is the reason the most successful projects in this area are based on this specific technology. Considering this fact, let’s have a closer look at the GAN networks.

What is GAN and how does it work?
GAN is a generative adversarial neural network. This is one of the algorithms of a classic machine learning without any teachers. The main concept of such a network lies in the simultaneous use of two networks. One of these networks realizes the mechanism of image generation and the second one realizes the discriminator’s mechanism. The generator’s goal is to create artificial images in accordance with the chosen category. The discriminator’s goal is to recognize the generated image and evaluate its correspondence either to the category of fake or real ones.
The discriminator is based on using convolutional neural networks (CNN). Such a network can recognize and segment an object (i.e. a face) on an image. In order to teach this model, a network has to process a very big number of images with pre-marked areas that contain the needed object. By processing such images, the algorithm gradually learns to recognize the needed objects independently. The learning sample may contain dozens and even hundreds of thousands of images. As for facial recognition, there are already available models that cope with this task almost perfectly (VGGFace, FaceNet, and others).
The generator, in its turn, creates an artificial image, using the arbitrary values from multidimensional normal distribution as a starting point, and passes it to the discriminator. The discriminator uses the backpropagation method to make allowances to the obtained values and then again passes them to the generator’s gateway. This process repeats in an infinite loop.
To put it short, here is how the two types of networks interact with each other. The neural network algorithm is described by an output mathematical function. Its value characterizes a certain probability of a generated image’s affiliation to the category of fake images. During the learning process, the discriminator strives to maximize this value and the generator wants to minimize it. In this way, by educating GAN, we strive to reach the balance between the generator and the discriminator’s network. When the balance is reached, we can say that the model reached the minimax state. After the education is completed, we get a generator model that can generate realistic images.
One of the application domains for generative adversarial networks is the creation of fake videos where the actor’s face can be replaced with a selected face. In this way, one can change almost any video.
The process of creating such a product consists of several stages:
- Forming the dataset for learning
- Facial detection and segmentation on the image
- Clearance of the obtained sample from garbage
- Image augmentation to increase the volume of source data
- Training of a new model on the obtained image base
- Replacement of the initial images with the desired ones
- Conversion of the video file
The model
In general, the model’s principle of operation can be displayed as an interaction of two elements – the coder and the decoder.
The coder’s main goal is to receive the image at the entry and code it into a vector image. Note that the coder does not consider the precise presentation of every face that you upload but tries to create an algorithm that will help to recreate the faces looking as similar to the entry images as possible.
The decoder’s goal is to take the vectors supplied by the coder and try to transform these presentations back into faces that will look similar to the entry images.
The training data
It is impossible to overestimate the importance of data quality for the model. A small model can efficiently function with a good data set and the most accurate model will display poor performance if presented with poor data. The absolute minimum should consist of at least 500 different images and the more data you have, the better it is for a model but there are certain limitations here. The adequate number of the needed images is usually within a range of 1000 – 10 000 images. Too many images (over 10 000) can harm the training process.
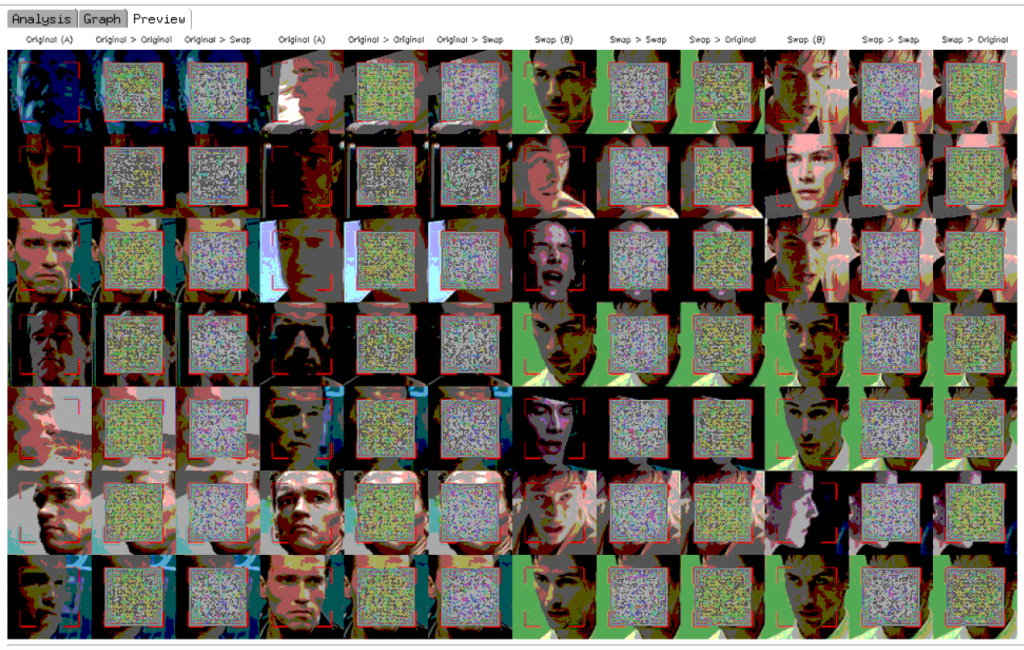
Picture 1. Images processing. The system starts new images generation.
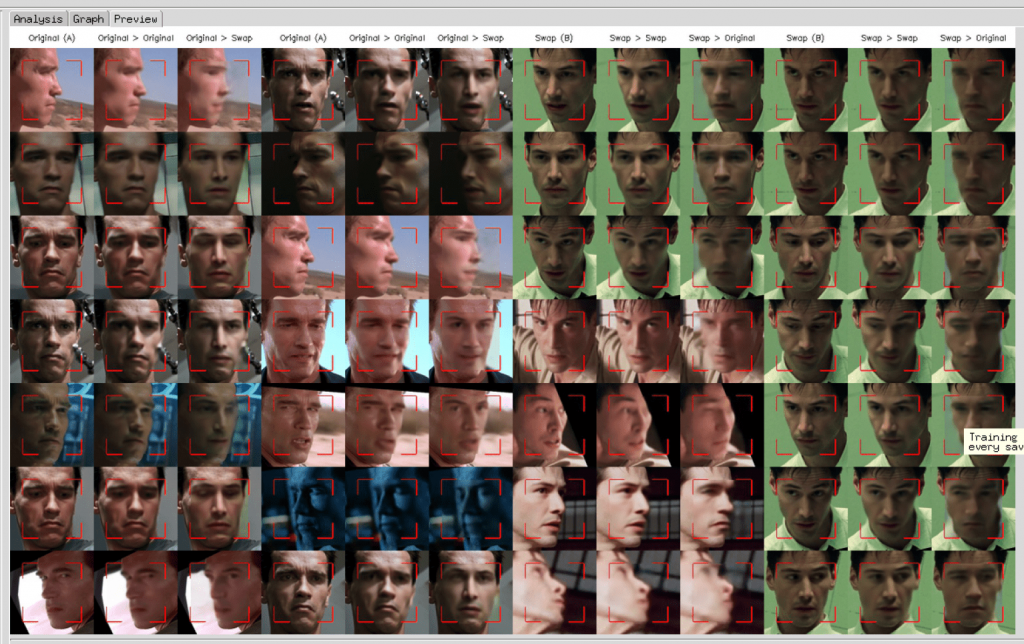
Picture 2. Images processing. The last stage.
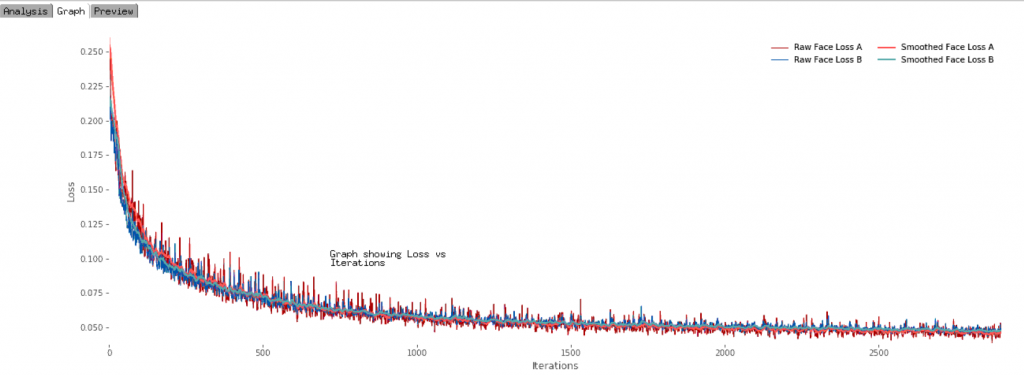
Picture 3. Graph shows decrease in number of learning errors related to the higher number of iterations.
The training process
It is highly recommended to conduct the training process on GPU and even on that condition, it might take a couple of days or even more. The accomplishment of such a task even if using the immensely powerful GPU is really challenging. The time solely depends on the selected model and the volume of the training sample. The size of the training sample also impacts the quality of the final result.
Because some open-source projects are publicly available (NVIDIA StyleGAN, Deepfake, Faceswap) any developer can actually play around with the GAN network and try their hands at the artificial images generation. While this opens a whole lot of new opportunities for the future of Machine Learning and image/video creation, this technology also implies certain risks (i.e. fraud, breached authentication) which must be considered in order to provide security of the online users and their data.


Comments